分布式 ID 生成器
分布式 ID 生成器是一种在分布式系统中生成全局唯一、有序的 ID 的算法或工具。在分布式系统中,由于各个节点之间需要共享数据或通信,因此需要一种机制来确保每个节点生成的 ID 是全局唯一的,以避免出现重复或冲突。分布式 ID 生成器就是在这种背景下应运而生的。
分布式 ID 生成器有很多种实现方案,常见的包括:
1. 数据库自增长序列或字段:利用数据库的自动递增功能生成 ID,适用于简单的分布式系统。
2. UUID(通用唯一识别码):UUID 是一个由微软公司开发的 ID 生成算法,生成的 ID 具有较高的唯一性。
3. Snowflake 算法:Snowflake 是 Twitter 开源的分布式 ID 生成算法,生成的 ID 是一个 long 型的值。其核心思想是使用 41bit 作为毫秒数,10bit 作为机器 ID(5 个 bit 是数据中心,5 个 bit 是机器 ID),剩余的 12bit 用于序列号。
4. Redis 生成器:基于 Redis 的分布式 ID 生成器,可以通过 Redis 的计数器功能生成 ID。
5. 基于开源库的生成器:如 Go 语言中的 idgenerator 库,Java 中的 Spring Boot ID 生成器等。
分布式 ID 生成器的设计和实现需要考虑性能、可扩展性、可靠性等因素,以满足分布式系统的需求。

CosId
CosId 旨在提供通用、灵活、高性能的分布式 ID 生成器。
CosIdGenerator : 单机 TPS 性能:1557W/s,三倍于 UUID.randomUUID(),基于时钟的全局趋势递增ID。
SnowflakeId : 单机 TPS 性能:409W/s JMH 基准测试 , 主要解决 时钟回拨问题 、机器号分配问题、取模分片不均匀问题 并且提供更加友好、灵活的使用体验。
SegmentId: 每次获取一段 (Step) ID,来降低号段分发器的网络IO请求频次提升性能。
RedisIdSegmentDistributor: 基于 Redis 的号段分发器。
JdbcIdSegmentDistributor: 基于 Jdbc 的号段分发器,支持各种关系型数据库。
ZookeeperIdSegmentDistributor: 基于 Zookeeper 的号段分发器。
MongoIdSegmentDistributor: 基于 MongoDB 的号段分发器。
IdSegmentDistributor: 号段分发器(号段存储器)
SegmentChainId(推荐):SegmentChainId (lock-free) 是对 SegmentId 的增强。性能可达到近似 AtomicLong 的 TPS 性能:12743W+/s JMH 基准测试 。
背景(为什么需要分布式ID)
在软件系统演进过程中,随着业务规模的增长 (TPS/存储容量),我们需要通过集群化部署来分摊计算、存储压力。应用服务的无状态设计使其具备了伸缩性。在使用 Kubernetes 部署时我们只需要一行命令即可完成服务伸缩 (kubectl scale --replicas=5 deployment/order-service)。
但对于有状态的数据库就不那么容易了,此时数据库变成系统的性能瓶颈是显而易见的。
分库分表
从微服务的角度来理解垂直拆分其实就是微服务拆分。以限界上下文来定义服务边界将大服务/单体应用拆分成多个自治的粒度更小的服务,因为自治性规范要求,数据库也需要进行业务拆分。但垂直拆分后的单个微服务依然会面临 TPS/存储容量 的挑战,所以这里我们重点讨论水平拆分的方式。
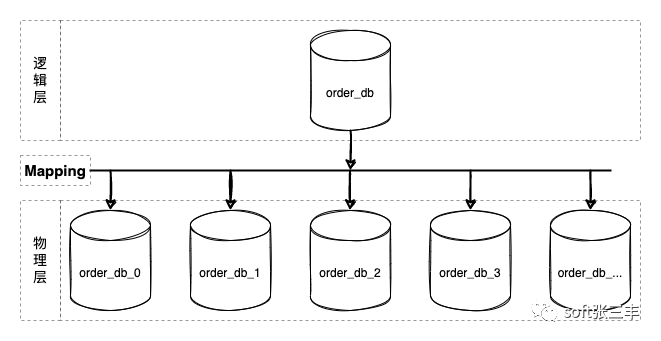
数据库分库分表方案是逻辑统一,物理分区自治的方案。其核心设计在于中间层映射方案的设计 (上图 Mapping),即分片算法的设计。几乎所有编程语言都内置实现了散列表(java:HashMap/csharp:Dictionary/python:dict/go:map ...)。分片算法跟散列表高度相似(hashCode),都得通过 key/shardingValue 映射到对应的槽位(slot)。
那么 shardingValue 从哪里来呢?CosId!!!
当然还有很多分布式场景需要分布式ID,这里不再一一列举。
分布式ID方案的核心指标
全局(相同业务)唯一性:唯一性保证是ID的必要条件,假设ID不唯一就会产生主键冲突,这点很容易可以理解。
有序性:有序性保证是面向查询的数据结构算法(除了Hash算法)所必须的,是二分查找法(分而治之)的前提。
吞吐量/性能(ops/time):即单位时间(每秒)能产生的ID数量。生成ID是非常高频的操作,也是最为基本的。假设ID生成的性能缓慢,那么不管怎么进行系统优化也无法获得更好的性能。
稳定性(time/op):稳定性指标一般可以采用每个操作的时间进行百分位采样来分析,比如 CosId 百分位采样 P9999=0.208 us/op,即 0% ~ 99.99% 的单位操作时间小于等于 0.208 us/op。
百分位数 WIKI :统计学术语,若将一组数据从小到大排序,并计算相应的累计百分点,则某百分点所对应数据的值,就称为这百分点的百分位数,以Pk表示第k百分位数。百分位数是用来比较个体在群体中的相对地位量数。
为什么不用平均每个操作的时间:马老师的身价跟你的身价能平均么?平均后的值有意义不?
可以使用最小每个操作的时间、最大每个操作的时间作为参考吗?因为最小、最大值只说明了零界点的情况,虽说可以作为稳定性的参考,但依然不够全面。而且百分位数已经覆盖了这俩个指标。
自治性(依赖):主要是指对外部环境有无依赖,比如号段模式会强依赖第三方存储中间件来获取NexMaxId。自治性还会对可用性造成影响。
可用性:分布式ID的可用性主要会受到自治性影响,比如SnowflakeId会受到时钟回拨影响,导致处于短暂时间的不可用状态。而号段模式会受到第三方发号器(NexMaxId)的可用性影响。
可用性 WIKI :在一个给定的时间间隔内,对于一个功能个体来讲,总的可用时间所占的比例。
MTBF:平均故障间隔
MDT:平均修复/恢复时间
Availability=MTBF/(MTBF+MDT)
假设MTBF为1年,MDT为1小时,即Availability=(365*24)/(365*24+1)=0.999885857778792≈99.99%,也就是我们通常所说对可用性4个9。
适应性:是指在面对外部环境变化的自适应能力,这里我们主要说的是面对流量突发时动态伸缩分布式ID的性能,
存储空间:还是用MySq-InnoDB B+树来举例,普通索引(二级索引)会存储主键值,主键越大占用的内存缓存、磁盘空间也会越大。Page页存储的数据越少,磁盘IO访问的次数会增加。总之在满足业务需求的情况下,尽可能小的存储空间占用在绝大多数场景下都是好的设计原则。
不同分布式ID方案核心指标对比
| 分布式ID | 全局唯一性 | 有序性 | 吞吐量 | 稳定性(1s=1000,000us) | 自治性 | 可用性 | 适应性 | 存储空间 |
|---|
| UUID/GUID | 是 | 完全无序 | 3078638(ops/s) | P9999=0.325(us/op) | 完全自治 | 100% | 否 | 128-bit |
| SnowflakeId | 是 | 本地单调递增,全局趋势递增(受全局时钟影响) | 4096000(ops/s) | P9999=0.244(us/op) | 依赖时钟 | 时钟回拨会导致短暂不可用 | 否 | 64-bit |
| SegmentId | 是 | 本地单调递增,全局趋势递增(受Step影响) | 29506073(ops/s) | P9999=46.624(us/op) | 依赖第三方号段分发器 | 受号段分发器可用性影响 | 否 | 64-bit |
| SegmentChainId | 是 | 本地单调递增,全局趋势递增(受Step、安全距离影响) | 127439148(ops/s) | P9999=0.208(us/op) | 依赖第三方号段分发器 | 受号段分发器可用性影响,但因安全距离存在,预留ID段,所以高于SegmentId | 是 | 64-bit |
有序性(要想分而治之·二分查找法,必须要维护我)
刚刚我们已经讨论了ID有序性的重要性,所以我们设计ID算法时应该尽可能地让ID是单调递增的,比如像表的自增主键那样。但是很遗憾,因全局时钟、性能等分布式系统问题,我们通常只能选择局部单调递增、全局趋势递增的组合(就像我们在分布式系统中不得不的选择最终一致性那样)以获得多方面的权衡。下面我们来看一下什么是单调递增与趋势递增。
CosId VS 美团 Leaf
CosId (SegmentChainId) 性能是 Leaf(segment) 的 5 倍。

开源的分布式ID
开源的分布式 ID 生成器有很多种,以下是一些较为知名的:
1. Twitter 的 Snowflake 算法:Snowflake 是 Twitter 开源的分布式 ID 生成算法,生成的 ID 是一个 long 型的值。其核心思想是使用 41bit 作为毫秒数,10bit 作为机器 ID(5 个 bit 是数据中心,5 个 bit 是机器 ID),剩余的 12bit 用于序列号。
2. 美团的 Leaf 项目:Leaf 是美团开源的分布式 ID 生成项目,基于 Snowflake 算法,支持 RPC 方式调用,据官方提供的信息,其 QPS 压测结果近 5w/s,tp999,1ms。
3. 百度的 UidGenerator:UidGenerator 是百度开源的一款分布式高性能的唯一 ID 生成器,基于 Twitter 的 Snowflake 算法实现,支持自定义时间戳、工作机器 id 和序列号。
4. 滴滴的 Tinyid:Tinyid 是滴滴开源的分布式 ID 生成器,基于 Snowflake 算法,适用于小规模的分布式系统。
这些开源的分布式 ID 生成器在不同的场景和需求下有着各自的优势和特点,可以根据实际需求选择适合的生成器来实现。
该文章在 2023/10/30 11:19:42 编辑过






 400 186 1886
400 186 1886


