什么是表分区?
表分区其实就是将一个大表分成若干个小表。
表分区可以从物理上将一个大表分成几个小表,但是逻辑上还是一个表。所以当执行插入、更新等操作的时候,不需要我们去判断应该插入或更新到哪个表中。只需要插入大表中就可以了。SQL Server会自动的将它放在对应的表中。对于查询也是一样,直接查询大表就可以了。
如何创建分区表
一、创建文件组
其实可以使用默认的primary组,但是为了更方便管理以及提高运行速度,所以还是应该创建几个分组。
1、使用SSMS创建文件组
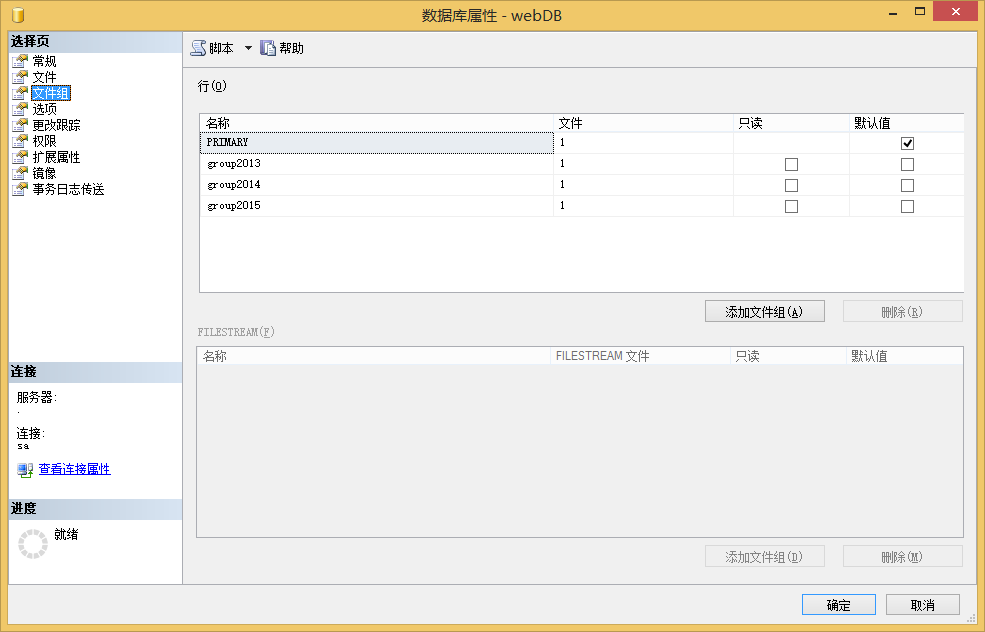
2、使用T-SQL创建文件组
--alter database <数据库名> add filegroup <文件组名>
alter database webDB add filegroup group2013
alter database webDB add filegroup group2014
alter database webDB add filegroup group2015
二、为文件组添加数据库文件
1、使用SSMS添加数据库文件
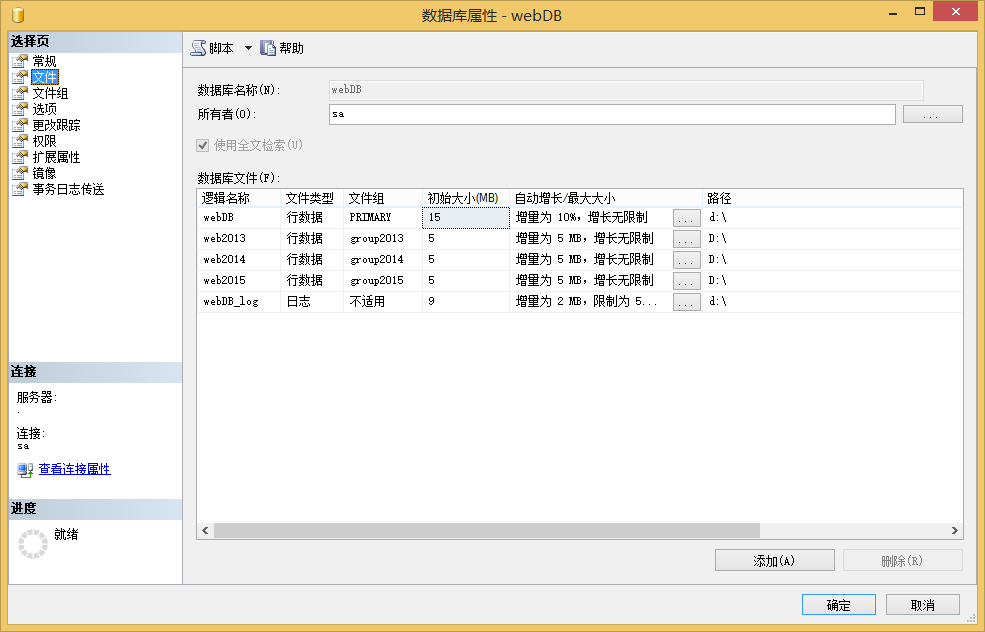
2、使用T-SQL添加数据库文件
--alter database <数据库名称> add file <数据标识> to filegroup <文件组名称>
alter database webDB add file
(
name='web2013',
filename='D:\web2013.ndf',
size=5mb,
filegrowth=5mb
)
to filegroup group2013
alter database webDB add file
(
name='web2014',
filename='D:\web2014.ndf',
size=5mb,
filegrowth=5mb
)
to filegroup group2014
alter database webDB add file
(
name='web2015',
filename='D:\web2015.ndf',
size=5mb,
filegrowth=5mb
)
to filegroup group2015
注意:尽可能的将不同的文件放在不同的硬盘分区里,或者独立硬盘中。这样可以加快SQL Server运行速度。
三、创建分区函数
分区函数用来告诉SQL Server用什么样的规则进行分区,这一步必须使用T-SQL脚本来执行了。
create partition function fenqu(datetime) --分区函数名
as range right --right分区方式 边界值去左表还是右表
for values ('2014-01-01','2015-01-01') --按这些值来分区
--group2013 : 2014-01-01 之前的
--group2014 : 2014-01-01 到 2014-12-31的
--group2015 : 2015-01-01 之后的
四、创建分区方案
create partition scheme SchemeFenqu --分区方案名
as partition fenqu --之前创建的分区函数
to(group2013,group2014,group2015) --跟放的文件组
创建完分区函数和分区方案后可以在存储中查看
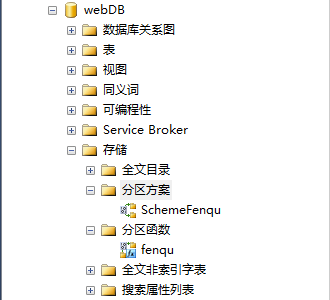
五、创建分区表
create table fenquTable
(
id int identity(1,1) not null,
name varchar(20) not null,
createTime datetime not null
) on SchemeFenqu(createTime) --调用分区方案
注意:不可以使用聚集索引,因为聚集索引是存在连续的物理地址中的,而表分区是将数据分别存储在不同表中的。
至此物理上分离的,逻辑上一体的分区表就创建完了。
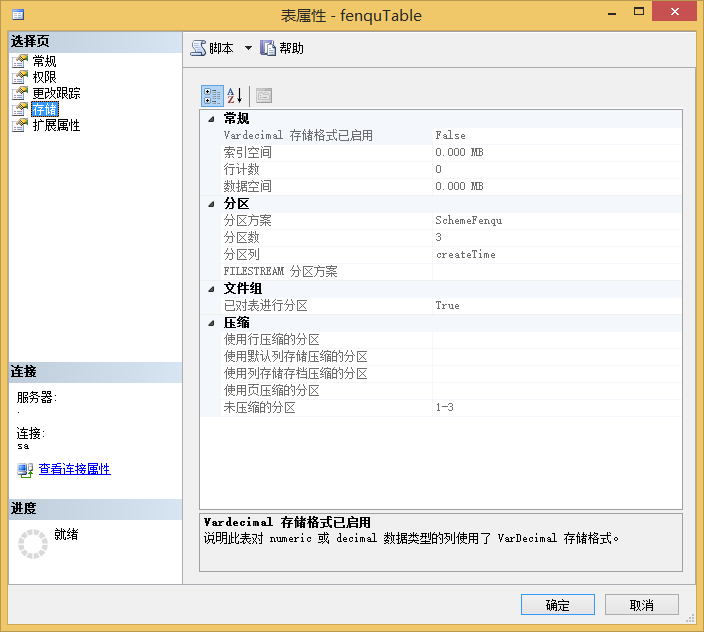
操作分区表
一、插入数据
--插入测试数据
insert into fenquTable(name,createTime) values ('隔壁老王','2010-01-01')
insert into fenquTable(name,createTime) values ('隔壁老张','2011-01-01')
insert into fenquTable(name,createTime) values ('隔壁老赵','2012-01-01')
insert into fenquTable(name,createTime) values ('隔壁老李','2013-01-01')
insert into fenquTable(name,createTime) values ('老李儿子','2013-10-01')
insert into fenquTable(name,createTime) values ('隔壁老田','2014-01-01')
insert into fenquTable(name,createTime) values ('隔壁老梁','2015-01-01')
insert into fenquTable(name,createTime) values ('老梁姑娘楠楠','2015-10-10')
跟插入普通表没有任何区别,不用管他放在哪个物理磁盘上。
二、查询数据
--查询数据
select * from fenquTable
查询也是如此,不用考虑哪个磁盘,逻辑上都属于同一个表,基本上看不出区别。如果需要查看哪条插入到哪个物理的分区表中,可以使用$partition函数查看。
--语法:$partition.分区函数名(表达式)
--查看该表达式下有多少数据
select $partition.fenqu('2015-01-01') --返回3
--查看分区表明细
select * from fenquTable where $partition.fenqu(createTime)=1
select * from fenquTable where $partition.fenqu(createTime)=2
select * from fenquTable where $partition.fenqu(createTime)=3
--查看分区表中的记录数
select $partition.fenqu(createTime) as 分区,count(id) from fenquTable
group by $partition.fenqu(createTime)
三、修改数据
select $partition.fenqu(createTime) as 分区,count(id) as 数量 from fenquTable
group by $partition.fenqu(createTime)
--分区 数量
--1 5
--2 1
--3 2
update fenquTable set createTime ='2015-01-01' where id = 1
select $partition.fenqu(createTime) as 分区,count(id) as 数量 from fenquTable
group by $partition.fenqu(createTime)
--分区 数量
--1 4
--2 1
--3 3
可以明显看到,跟普通修改没有区别,SQL Server可以自动帮我们重新划分分区,将数据从第一个分区移动到第五个分区中。
普通表转分区表
上面介绍了如何在创建表的时候进行分区,但往往我们需要的是将现有的普通表在数据保留的情况下进行分区。
普通表一般都有主键,同时还是聚集索引。分区是以某个字段为条件进行的,而除了这个字段其他字段是不可以创建聚集索引的。所以需要先删除表中的聚集索引,再新建一个聚集索引。
--删除主键,自动同时删除索引
alter table newTable drop constraint PK_newTable
--创建主键,但不创建聚集索引
alter table newTable add constraint PK_newTable
primary key nonclustered --非聚集
(
id asc
) on [primary]
--然后给我们亲爱的时间创建一个聚集索引
create clustered index CT_newTable on newTable(createTime)
on schemeFenqu(createTime) --并调用分区方案
--然后再查询分区,发现数据保留情况下,已经将数据按规则进行分区了
select $partition.fenqu(createTime) as 分区,count(id) as 数量
from newTable group by $partition.fenqu(createTime)
添加分区
向上面只分了3个区,而15年以后的都存在第三个分区中,到16年还是会存在这个分区中,这时候需要再新加一个16年的分区。
添加新的分区意味着要新建一个文件组和文件来存放这个分区表,然后在分区方案中用到这个文件组,最后再修改一下分区函数的规则即可。文件组和分区数量要保持一致。
--创建文件组
alter database webDB add filegroup group2016
--添加数据库文件
alter database webDB add file
(
name='web2016',
filename='D:\web2016.ndf',
size=5mb,
filegrowth=5mb
)
to filegroup group2016
--修改分区方案
alter partition scheme SchemeFenqu
next used group2016
--修改分区函数
alter partition function fenqu()
split range('2016-01-01')
--添加2016年数据
insert into newTable (name,createTime) values ('16年小明','2016-03-05')
--查看分区及统计
select $partition.fenqu(createTime) as 分区,count(id) as 数量
from newTable group by $partition.fenqu(createTime)
删除分区
删除分区就是将分区函数中多余的边界值删除。
如:2013,2014,2015,2016 现在需要将13年和14年进行合并,删除13年的分区。
--查看分区及统计
select $partition.fenqu(createTime) as 分区,count(id) as 数量
from newTable group by $partition.fenqu(createTime)
--分区 数量
--1 4
--2 1
--3 3
--4 1
--删掉该边界值
alter partition function fenqu() merge range('2014-01-01')
--再次查询
select $partition.fenqu(createTime) as 分区,count(id) as 数量
from newTable group by $partition.fenqu(createTime)
--分区 数量
--1 5
--2 3
--3 1
拆分分区
有的时候某一分区中数据量过大,需要将这个分区再次拆分为多个分区,以加快访问速度。
拆分分区的操作其实与添加分区类似,首先要添加文件组、文件、修改分区方案、修改分区函数(新增一个边界值)。
如:2014,2015,2015年6月份以上一个 6月份一下一个。
--查看分区及统计
select $partition.fenqu(createTime) as 分区,count(id) as 数量
from newTable group by $partition.fenqu(createTime)
--分区 数量
--1 5
--2 3
--3 1
--创建文件组
alter database webDB add filegroup group2014_2015
--添加数据库文件
alter database webDB add file
(
name='web2014_2015',
filename='D:\web2014_2015.ndf',
size=5mb,
filegrowth=5mb
)
to filegroup group2014_2015
--修改分区方案
alter partition scheme SchemeFenqu
next used group2014_2015
--修改分区函数
alter partition function fenqu()
split range('2015-06-01')
--查看分区及统计
select $partition.fenqu(createTime) as 分区,count(id) as 数量
from newTable group by $partition.fenqu(createTime)
--分区 数量
--1 5
--2 2
--3 1
--4 1
分区表转普通表
--修改分区函数 将边界值都删除
alter partition function fenqu()
merge range('2013-01-01')
alter partition function fenqu()
merge range('2014-01-01')
alter partition function fenqu()
merge range('2015-01-01')
alter partition function fenqu()
merge range('2015-06-01')
select $partition.fenqu(createTime) as 分区,count(id) as 数量
from newTable group by $partition.fenqu(createTime)
--这时只有一个分区了
--分区 数量
--1 9
这样虽然只有一个分区了,但是查看数据表存储位置,是否进行分区:True,分区数1.
--重新建立聚集索引
create clustered index CT_newTable on newTable(createTime)
with(drop_existing=on) --如果存在则删除
on [primary]
删除分区索引后,重新建立聚集索引,这时再此查看数据表的存储位置,是否分区:Flase。






 400 186 1886
400 186 1886


