任意文件读取&下载漏洞的全面解析及利用
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
前言本人在近期实战时也是挖到了任意文件下载漏洞,想着如何对此漏洞进行最大化利用,遂花了点时间去学习此漏洞的利用,发现网上知识点过于分散,正好看到社区这方面的知识很少,于是就想着自己写一篇关于任意文件读取的漏洞文章。 漏洞原理在目前的很多业务系统中,很多上传点都无法进行利用,最常见的就是上传一个文件不返回上传路径,即使我们成功上传了马子也无法进行后续连接啊。虽然不返回路径,但是我上传的文件我应当可以进行读取的,所以也就衍生出很多网站采用一个接口的方式进行文件的下载&读取的需求,但是这种方式真的安全吗? 在日常中,我们经常会遇到以下几种下载文件的url格式 首先说第一种url,这种url存在的安全问题很少,如果非要测的话,可以对后面的文件名和后缀进行Fuzz,从而在文件中获取敏感信息等 接着第二种url格式,这种url既然id参数可控,那么我们可以对此参数进行SQL注入,服务器既然接收了id参数,那么应该会对id参数进行数据库查询操作。如果这个id值有规律,那么也可以对id值进行遍历操作。
最后第三种url格式,此种安全问题就是可能存在任意文件下载漏洞,也是本文着重讲解的主要点。 在Linux和Windows系统中,有点开发经验的师傅都知道,在系统中可以用绝对路径和相对路径来表示一个文件的地址,此处不作相对路径和绝对路径的讲解。./在系统中表示当前目录,../为当前目录的上一级目录。这样的话安全问题就显而易见了,我们只需要在我们控制的文件名前加上 ../ 跳到上一级目录,然后一直跳就可以跳到根路径了,想下载&读取需要的文件就可以造成任意文件读取漏洞了。 漏洞位置根据功能点判断文件上传后的返回url中、文件下载功能,文件预览功能,文件读取功能 如果上诉功能点存在那么可以抓包根据下面的url判断 根据url判断绕过思路1、Fuzz文件简单粗暴,但是burp发包的时候注意编码问题,取消勾选自动url编码
2、url编码绕过
常用绕过一般是后两种,点一般不会被过滤,因为文件名中间也会存在一个 . 3、二次编码绕过
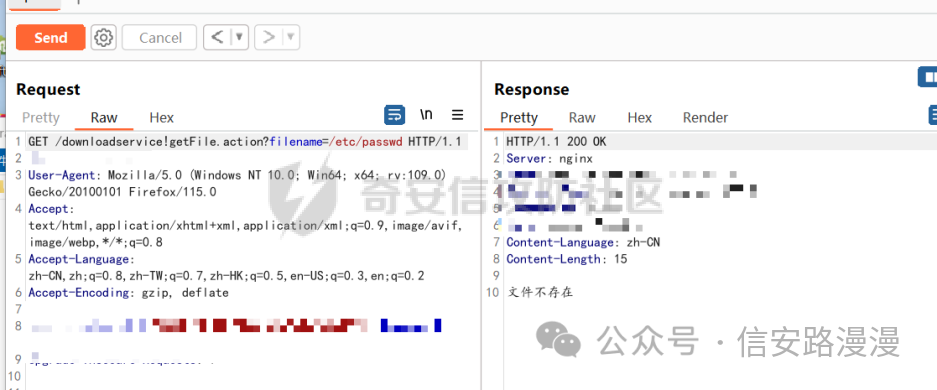
4、将 / 替换为 \ 绕过5、%00绕过?name=.%00./.%00./.%00./.%00./etc/passwd 6、双写绕过有些代码会进行过滤,会把 ../ 置空,那么利用 ....// 代替 ../ ,利用 ..// 代替 / 这种情况很少见,视情况而定 漏洞利用Linux 系统下利用思路:1、读取/etc/passwd 和/etc/shadow 进行撞库解密,如果能解出来那么直接ssh登录 2、读取/root/.ssh/id_rsa 等ssh登录密钥文件,从而通过密钥免密登录服务器 3、读取/root/.bash_history 终端命令操作记录,进而从命令记录中推测出web源码位置,审计源码进行getShell 4、读取数据库配置信息,远程连接数据库,进行脱库等操作 5、读取/var/lib/mlocate/mlocate.db 文件信息,获取全文件绝对路径,想下载啥就下啥了 总结:以上一些利用思路,核心思想不过与对数据的获取或者是权限的获取,黑客的目的也不过如此,数据和权限这两者其实是可以互相转换的,当一个无法进行利用时,那么可以转换一下思路对另一个进行利用 Windows 系统利用由于windows服务器特性,可以分盘操作,导致我们黑盒测试很难知道目标服务器是否存在其他盘符,即使知道了盘符也很难知道绝对路径,所以window系统很难利用此漏洞。 修复建议1、限定文件访问范围,在php.ini等配置文件中配置open__basedir限定文件访问范围 2、禁止客户端传递../这些敏感字符 3、文件放在web无法直接访问的目录下。 实战案例在点击文件下载的时候发现url格式如图所示,当输入任意字符时会返回文件不存在,如果输入存在的文件名则会直接下载文件
因为服务器是Linux系统,所以我们可以读取/etc/passwd文件来判断是否存在漏洞。依次进行 ../ 跳目录测试
发现测试了许久都是返回文件不存在,那可以考虑当前web程序可能存在防护了,一般开发者在代码层进行防护的话,一般都是过滤掉 . / 这种字符进行防护,根据上面提到的方式进行绕过处理
单次编码不行,那就继续在原来编码的基础上进行二次url编码,再测试一波,最终也是验证成功漏洞存在
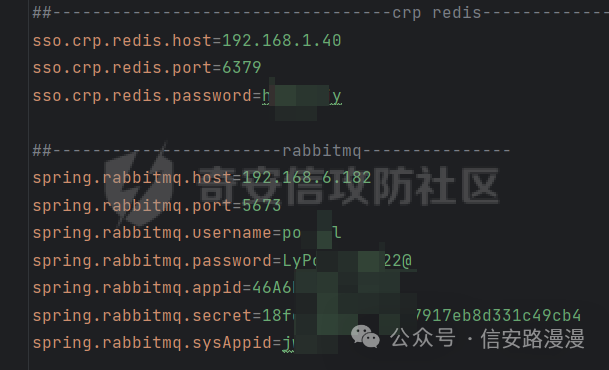
验证漏洞存在了,如果是在未授权的情况下进行利用,那么可以直接提交漏洞了;如果在已授权情况下,还想进一步对漏洞进行利用更深入,那么可以考虑怎么进行更深入的利用呢。 我先是读取/root/.bash_history 内容,根据命令操作拼接路径,先是下载了目标网站的源码,我也是从源码中读到一些数据库账号密码等信息,可惜都是内网,我不能利用到。如果你是代码审计大牛,那么可以直接开始审计代码,从代码中挖掘漏洞,进行getShell。很显然我不是
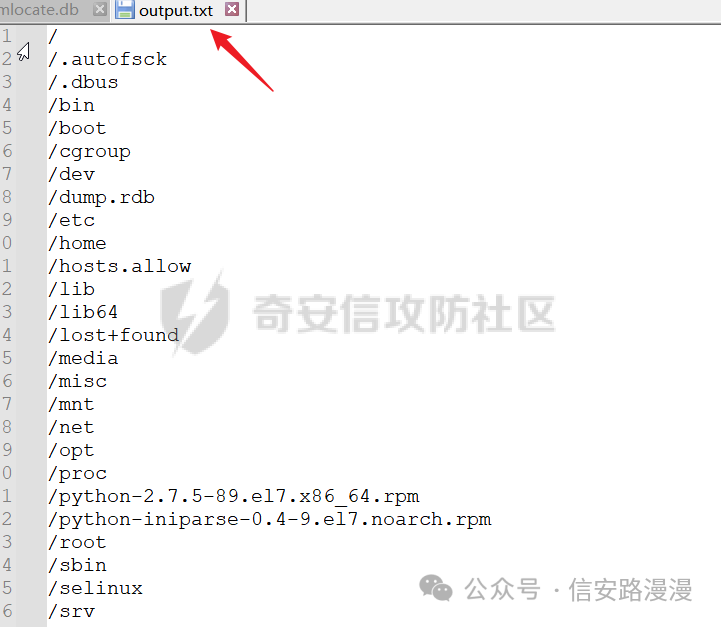
后来我也是想着下载ssh公钥文件等思路,可惜的是,此目标网站只对外开放web服务端口,所以我无法进行其他服务的攻击利用。 既然从目标中获取权限不行,那我转换一下思路,通过漏洞获取数据,再从获得数据中提取信息,从而获取系统的更高权限。 Linux下有mlocate.db文件,此文件介绍如下,我可以下载这个文件,再从这个文件中获取其他文件的绝对地址,这样的话我就可以下载到目标服务器上任意的文件了
将获取到的全文件数据库解出明文,然后从明文中翻找重要文件进行下载
在计算机中,重要文件,无非就是数据和权限相关,所以我们主要找备份文件和数据库文件 .rar、.zip、.7z、.tar、.gz、.tar.gz、.bz2、.tar.bz2、.sql、.bak、.dat、.txt、.log、.mdb 在全文件路径中搜索以上格式文件,再重点关注一下不同路径下的文件,因为Linux系统中不同文件夹的作用是不一样的,最后,我也是成功找到不少数据库备份文件rdb
后来也是因为这提取的数据量过于庞大,文件太大打开太卡了,只能自己写一个脚本提取数据了
最后也是成功将数据提取出来,可见成功获取到全站1.6W用户数据,一不小心就脱库了呀,事后本人也是提交了漏洞并将相关数据全部销毁。 原文来自:https://forum.butian.net/share/2664 该文章在 2025/5/14 10:03:22 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886